The web is a treasure trove of information. However, while we can easily read the information displayed on a website, scrapping the very same information algorithmically for data analysis is not so simple. Thus for this blog post I am going to demonstrate a web scraping example using the Go programming language and an excellent package written in Go, designed for web scraping, called Colly. Go is a modern, no nonsense, easy to use programming language that is continuing to grow in popularity. I have used Go to build the backends for several websites and I have found the experience very enjoyable. Colly adds numerous functions to Go that makes web scraping straightforward.
The example below is how to web scrape the store addresses of every CVS Pharmacy in the United States. Once we have scraped the store addresses we can then use a geocoder to convert the addresses into longitude and latitude coordinates. With these coordinates we can then perform various GIS analyses such as a proximity analysis to locate the nearest CVS store given any location in the world. I will demonstrate proximity analysis with this CVS store data in the next post. Here the focus is only on web scraping.
Getting Started
I am going to assume that you have some facility with programming and Go or a similar language. To download Go and install it on your computer follow these instructions. The Tour of Go is an excellent tutorial to begin to get comfortable coding in Go. Once Go is installed create a project directory and a Go module to allow Go to install the packages needed to perform the web scraping with the following commands:
mkdir cvs-addresses && cd cvs-addresses
go mod init colly-cvs-example
Next be sure that Colly is installed by using the go command:
go get -u github.com/gocolly/colly/...
When scraping the web it is important to explore the webpages that contain the data we want. We have to go step by step, just as our scraper will, and inspect the key HTML elements that we need to inform our scraper of what to look for on each webpage. Let’s do that now.
The first webpage to look at is the page with links to the pharmacies for each state on the CVS website. This page will be the starting point for our web scraper. It looks like this:

However this is just the human readable format for the webpage. Our scraper sees the website differently, as a tree of HTML elements and attributes. To see both the view above and the HTML document click F12 on your keyboard, which brings up the browser’s developer tools and looks something like the following:
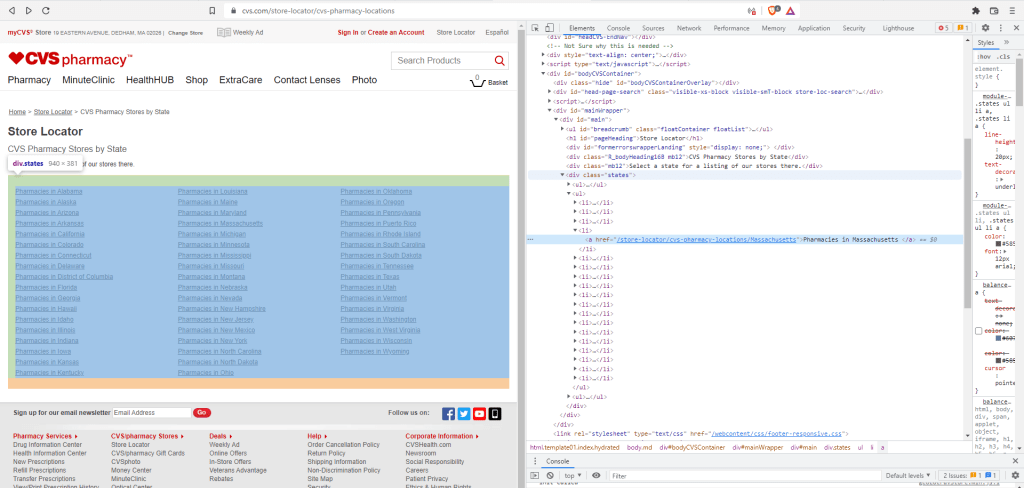
On the left is the page as we see it when we navigate to it (minus the blue and green colors which are just highlighting the selected sections from the right pane). On the right is the developer’s view, which contains the HTML and CSS code that generates the view on the left. It is this code on the right that our scraper needs to find the links to each of the CVS state specific webpages. For example in the right pane above, the link to the webpage for the Massachusetts pharmacies is in the second horizontal blue line. It has an HTML element a (“a” is for anchor) with an href attribute linking to the webpage of Massachusetts stores. As we will see below these HTML elements are what we need for the scraper.
Following the link to the Massachusetts webpage we get the following:
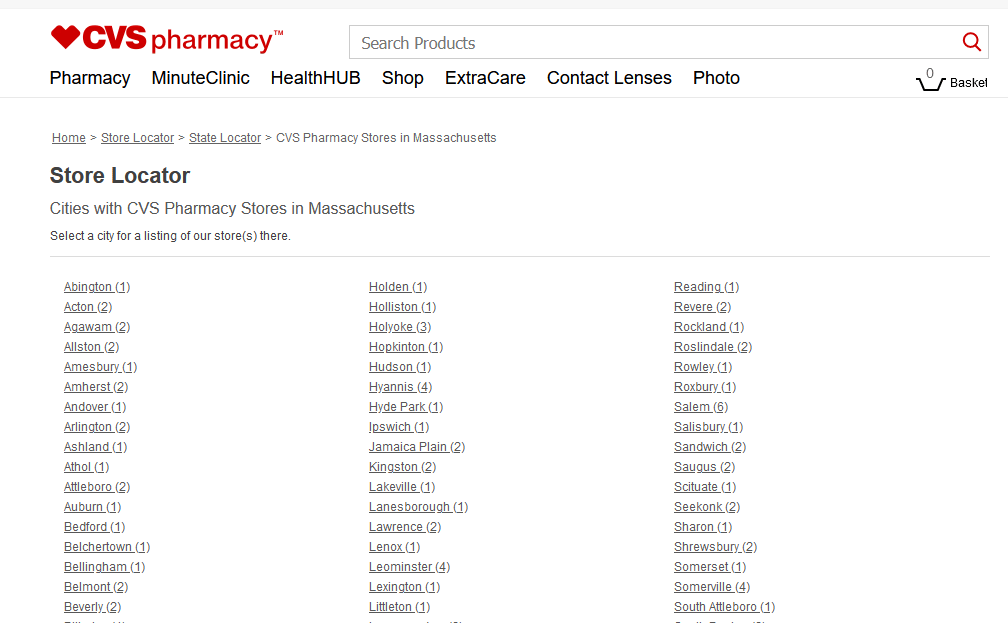
Here we have a list of all the towns in Massachusetts with a CVS pharmacy and the number of pharmacies in the town.
If we again press F12 to open the developer tools to see the corresponding HTML, then the page is transformed into the following view:
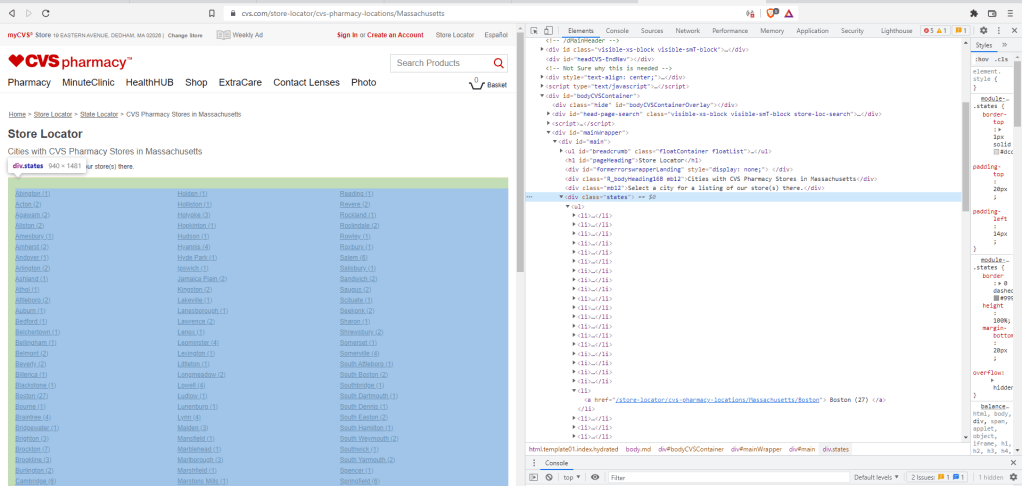
On the left, once again, is the list of Massachusetts towns and the number of pharmacies per town, while on the right is the HTML document of that same list of towns. As above we locate the HTML elements that we need to navigate to a town’s CVS address webpage. In this case the elements are a div (division elements) with a class attribute called “states” followed by list elements, li, which contain a (anchor) elements with href attributes that hold the desired web-links. For example the link to Boston is open on the right hand pane.
And finally once when we click a town then we see all the CVS locations in the town. For example here are the first 9 of 27 locations in Boston:
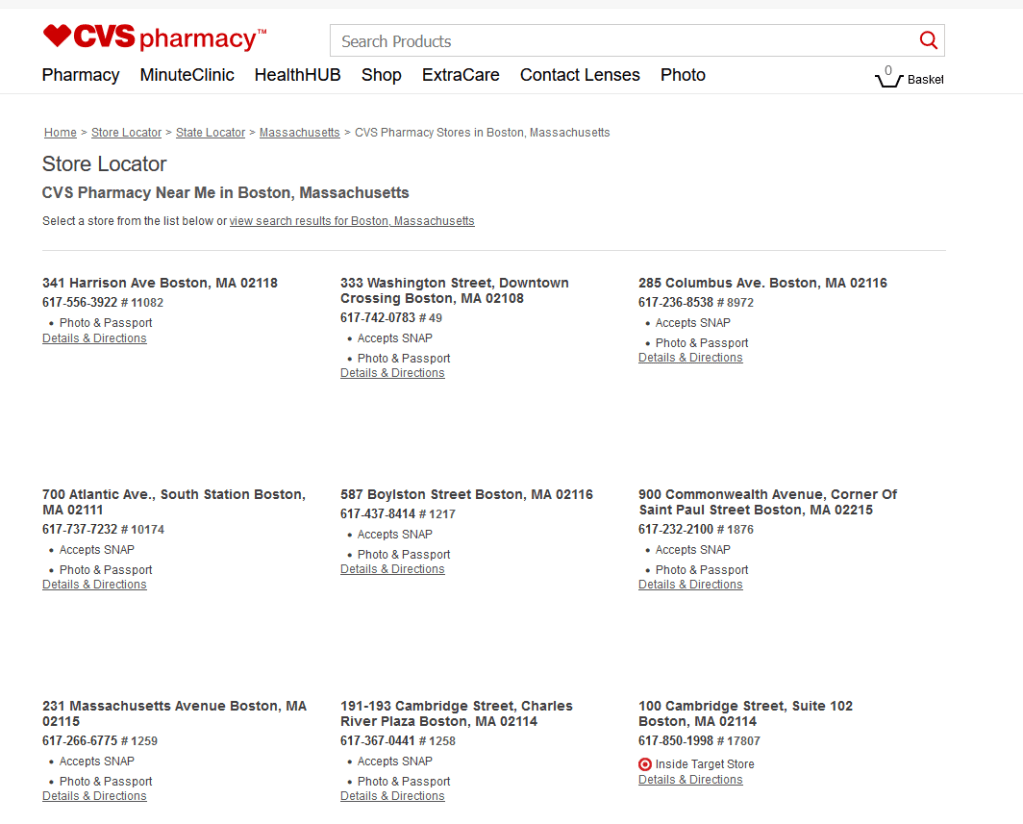
To open the developer’s tools and find the relevant HTML elements this time, we right click on an address and choose inspect as seen below (note: we could have used inspect above instead of F12):
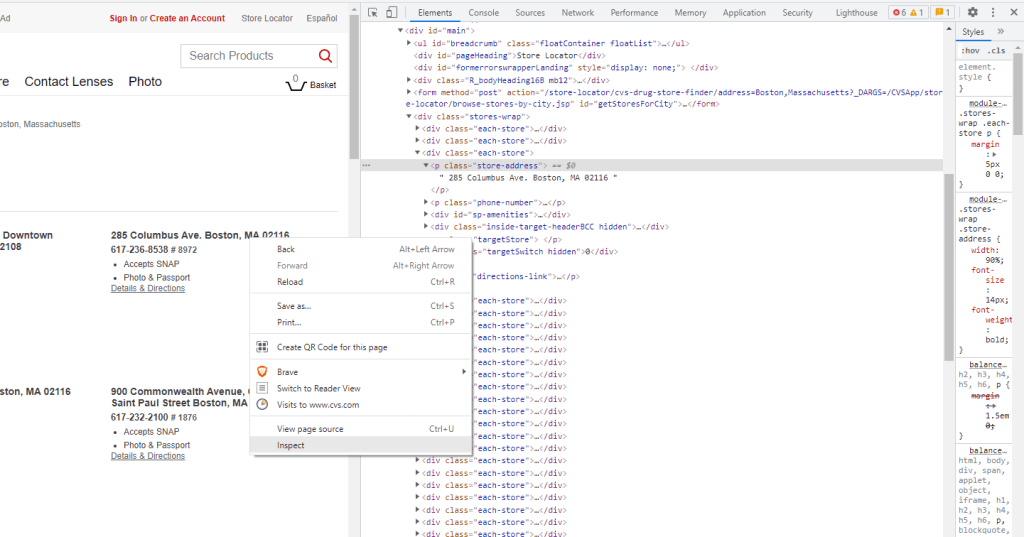
Thus we see that the address for 285 Columbus Ave is in an HTML element called p (paragraph elements) with a class attribute equal to “store-address”. These HTML elements are the same for address in each town. Lastly with this HTML element we can then obtain the address.
This may seem like a lot, but HTML is actually quite logical and something one gets accustomed to reading with practice. See the Mozilla Foundation’s excellent free course on web development to learn more about HTML and the other aspects of web design. From a scraping point of view we usually don’t need to know all that much about web design in order to retrieve the desired information. But understanding HTML elements is essential, so definitely check out that course if you want to learn more.
Enter Go Colly
With the general strategy of what HTML elements we need our scraper to use as webpage landmarks and the sequence of webpages that we need to traverse to acquire the pharmacy addresses, we are ready to actually write the Go code. Colly’s collector object will be used to grab each store address. The full CVS store scraper code is on my GitHub if you want to jump ahead and take a look.
I will walk through the Go code to try and provide a better understanding of the different commands. The first set of code is below:
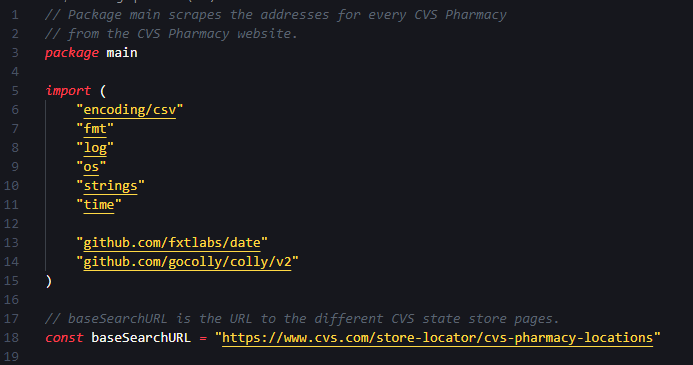
Comments are in grey preceded with //, package main denotes the beginning of the program and the import section contains the packages that are used below to do the work. Because Go has the nice feature of prepending package names before function names, it is easy to see where each of these packages is used below. Note that I am using VSCode which auto-imports the required packages.
The last line of the code snippet has the constant baseSearchURL defined as the website URL that we saw above. It has the web-links to each CVS state store page and is where the scraper starts its journey.
With the needed packages imported it is time to turn to the main function where the action occurs.

Line 22 returns a date string, like “2020-01-01” to prepend to the file name that we will use to store the addresses.
Lines 25 through 31 performs the following operations: create a file name with the date, create a file, checks for errors on file creation, and then the defer statement will close the file at the end of the program.
Lines 33 through 38 prepare the program to write specifically to a csv file and set a header as the first line of the file. There is only one column here but even so I still prefer to work with csv files as the database system in the next post, Postgres, works well with csv files.
The next section of code is where Colly comes into play:

The first thing we do on line 42 is instantiate a Colly collector, named c. A Colly collector is the primary object that performs the web scraping. Each collector has a number of default settings most of which we will use. But limit rules are added on lines 48 through 51. These rules reduce how quickly requests are made from the collector to the CVS website. We do this to be good web citizens in not burdening the website and to decrease the chance our IP gets banned.
The next snippet uses the HTML elements we identified above to traverse to each state and town webpages that we explored above.
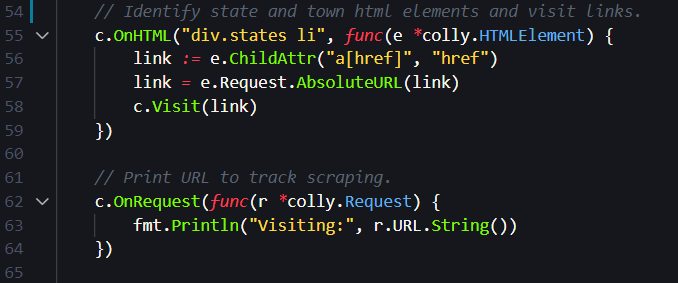
The above snippet uses the OnHTML method, which accepts two arguments. The first argument is a query string, div.states li, that looks for div HTML elements with a class attribute called “states” and a list item, li, in that div block. You can see this structure explicitly in the image of the webpage that we looked at above. Note these query strings are called CSS selectors and they have special formatting rules that make accessing information in on a website easier.
The next argument to OnHTML is a function that extracts the web-link contained in the a element contained within the li block. The link is then formed into a proper web URL on line 57 and the collector visits the link on line 58. This is how the collector starts on the webpage with a list of states and moves to the webpage with CVS pharmacy addresses within a town.
The next method that is called on line 62 is OnRequest which takes a function and executes that function when the collector makes an HTTP request to a website. Here OnRequest will print the visited website to the console. This allows us to track the collector as it traverses the different state and town websites in real time.
The code that retrieves a store’s address once the collector lands on the town’s webpage is below:

Once again the OnHTML method is invoked. This time the query string, p.store-address means that the collector is looking for HTML elements of type paragraph, p, with a class attribute called “store-address”. These HTML blocks can again be seen above when we looked at the website with the store addresses.
The function we pass to OnHTML in the second argument then extracts the store address, trims white space from the front and back of the address, prints the address to the console on line 70, and writes it to the csv file that holds the addresses on line 71.
Lines 75 and 76 simply starts the collector at the initial webpage and checks for any errors.
The Results
With the scraper complete we run the program and retrieve the addresses for all 9,917 CVS pharmacies in the USA. A task that would have been quite tedious by hand is complete in a few minutes. The first 10 store addresses are below:

